
When you purchase through links on our site, we may earn an affiliate commission (details)
“Is Google Gonna Slap Me For [Insert Name of Content Generation Method]?”
by Antone Roundy | 6 Comments | Blogging, SEO
Google caused another ruckus online a few days ago when they laid down the law against content mills. Some people are complaining, others are wondering what took 'em so long, and still others are getting nervous, wondering whether their favorite content generation method is going to get Slapped next.
While nobody knows for sure where or when the axe will fall, it's not too difficult to guess which sorts of techniques are most at risk. In short: creating value = good, leaching off the value others create = questionable, spewing garbage = bad.
There's a whole continuum of blogging methods, each of which creates a different amount of value and carries a different amount of risk.
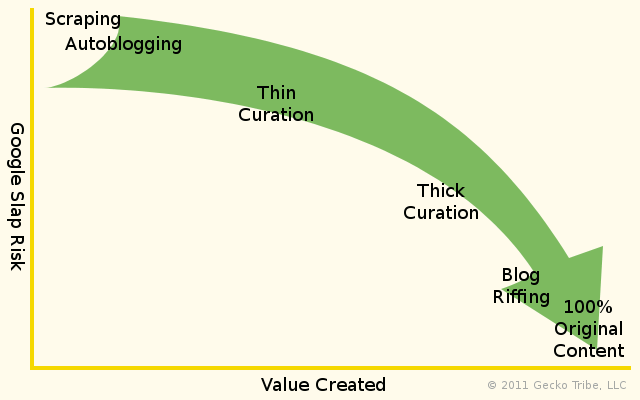
Scraping
In this context, scraping means using automated tools to copy content from a website without permission and republish it. Not only is the content completely unoriginal, but it's also stolen.
Just to be clear, the word scraping is used to describe a method of creating an RSS feed for a site that doesn't automatically publish one. Some people use scraping tools to create feeds for their own websites. Others use them to steal content. As long as its done with the consent of the publisher, it's not inherently bad. It's when scraping tools are used to violate copyrights that it runs afoul of ethics.
Autoblogging
Autoblogging, or using fully automated tools to import content and post it to a blog with no human intervention, is the next lower on the value add scale, and next highest on the Google Slap risk scale.
To the degree that content sources are carefully selected and the autoblog does something unique (beyond attempts to fake uniqueness, like using automated translation tools to convert content from one language to another and back) -- for example, combining content from multiple sources -- autoblogs may not be entirely without value. However, since the content is entirely unoriginal, the value add is relatively low and the risk relatively high.
Thin Curation
Curation is the process of selecting content written by others and republishing it or publishing excerpts from it. What I call "thin curation" happens when nothing more than a sentence or two of original commentary (if any) is added. The value add is almost entirely in the selection of high-quality content.
Depending on how good the selection is, and how difficult it would have been for readers to find the content on their own, curation blogs can be very valuable. But since the content is almost entirely unoriginal, they're more at risk than more original blogs. If Google can't automatically recognize that value is being added, who knows what they'll do.
Thick Curation
Thick Curation is my term for curation blogs where someone else's content is the main focus, but which contain more original commentary than Thin Curation blogs. There's no sharp line separating the two.
More original ideas (assuming the commentary is good!) means more value added. And it stands to reason that a higher percentage of original content would reduce the risk of being penalized.
Blog Riffing
Blog Riffing is like Thick Curation, but with enough original commentary that the original content becomes the main focus. Someone else's content serves as the seed or inspiration for a post, but what grows from the seed stands on its own.
100% Original Content
It could be argued that nothing 100% original exists -- that so-called "original" blog posts were inspired by something, even if the inspiration has been so internalized that it's not even recognized. Without waxing too philosophical about that, we'll call anything "original content" that doesn't quote any source of inspiration, and isn't plagiarism.
Certainly, not all "original" thoughts, Blog Riffs, or curators comments have the same value. But at least we can say that all other things being equal, the greater the proportion of the content that's original, the greater the proportion of the value that's unique. And the more unique value you generate, the lower your risk of getting Slapped.



March 1st, 2011 at 10:03 am
You know, it's kind of obvious when it's laid it out like this, eh? :-)
It's simple; for the best results create something new and original. Like anything in life of value, there are no long term easy solutions or shortcuts.
I wonder if people who constantly search for easy and fast ways to game the system wouldn't just be better off focusing on ONE thing and putting all their energy towards that. Ironically, they would probably end up working less and earning more in the long term.
But hey, it's an instant gratification world we live in and people like to chase objects that are shiny & easy.
March 1st, 2011 at 10:36 am
Yep. You can use better tools to shortcut the "grunt work" or improve the process in other ways. But the part of the process where the value is created almost always takes work.
"A monkey, although dressed in the magistrate's robes, is still a monkey." Easy buttons may be very efficient at cranking out content, but garbage is garbage, no matter how much of it you have.
March 1st, 2011 at 2:30 pm
I'm so glad I use only original content. It costs me a bit, not only in money but time as well, but at least I am sleeping peacefully.
I started building my site as a retirement hedge ... I would hate Google to come along and dance on my site...
Thanks for the post Antone.
March 2nd, 2011 at 4:28 am
Put me done in the "wondering what took ‘em so long" camp.
The shame is that even now there will be characters that still don't get it and rather than creating their own original work will be seeking ways to second guess and circumvent the rules.
March 2nd, 2011 at 7:55 pm
Original content can't be beat. It takes time and effort but pays off well. I have sold four sites so far and each of them were 100% original content.
Effort and hard work pays. Always did always will.
February 26th, 2012 at 7:34 am
It always shocks me when I see someone go to another website and steal the content and republish it on their site.
I have worked with 2 people who have done this... I ask: "Would you walk into a store and grab what you wanted and run out of the store without paying?" Their answer is always no, but the internet is a different story to them, they think it's ok to steal content and run!
I have also heard from a thief: "Oh well, they will just have to get over it."
People don't get it!
Virginia